When One Worker Can't Keep Up: Scaling Projections
Scale event sourcing projections with partitioned processing, track-based gap detection, and streaming. Learn how Ecotone handles concurrent transactions.


Scaling event sourcing projections isn't just about adding workers. The first problem you hit when moving from "one request at a time" to "many in parallel" isn't throughput — it's correctness. And the way you solve it is itself your first scaling decision: the choice directly sets your scaling ceiling.
The problem of concurrent writes may lead to projection losing an event with: No error. No log entry. No exception. The read model will be permanently wrong, and you will not find out until someones reports the problem.
Simple event sourcing libraries and home-built solutions often have no awareness of this problem. The projection logic looks correct in development — because your dev environment runs one request at a time. It is only under production concurrency that events start silently disappearing.
This connects directly to scalability. The decision on how to solve this problem shapes how your projections will scale – which is why we need to discuss it first.
How Global Tracking Projections Work
A global tracking projection reads from a single ordered log – your Event Store stream. That stream contains every event written, regardless of which aggregate produced it. Tickets, Orders, Users, Payments – all interleaved into one sequence.
Each event gets a unique, monotonically increasing sequence number the moment it is appended. The projection's job is straightforward:
- Read the next batch of events after its last known position
- For each event, run any matching handlers
- Store the new position -- the highest sequence number processed
On the next run, it picks up where it left off.

This model is simple and works perfectly – when one process writes events at a time. It is what most tutorials show. Then production hits, and concurrent writes happen.
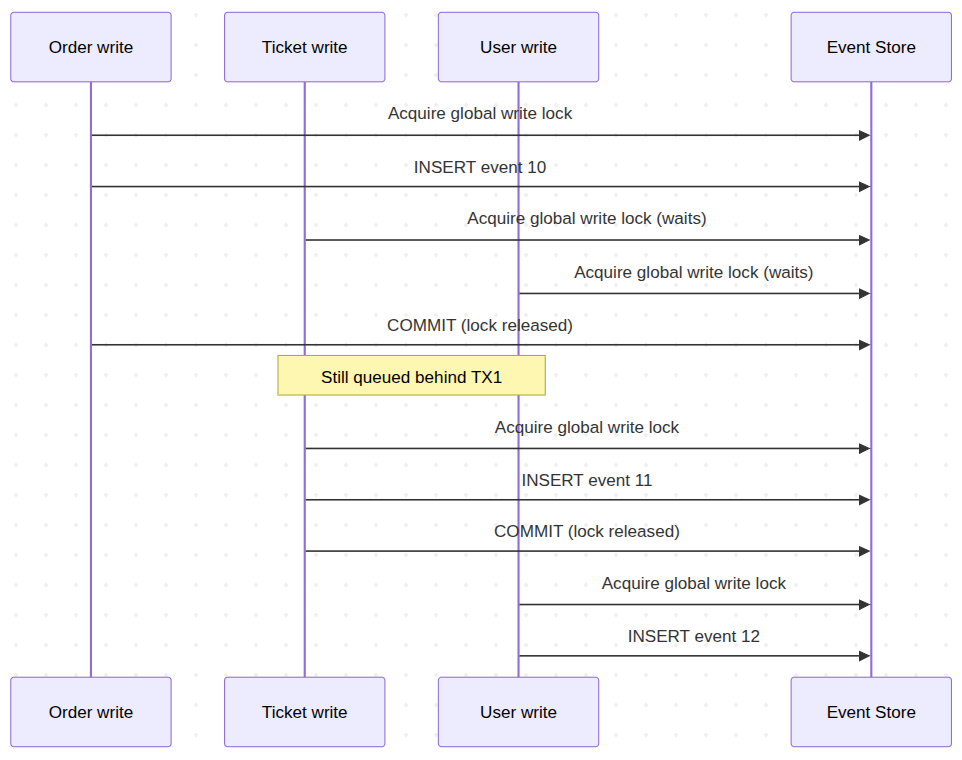
The Concurrent Transaction Problem
Two users register tickets at the same time. Two database transactions start in parallel:
- TX1 writes an event for Ticket-A. The database assigns it position 10. TX1 is doing extra work -- a constraint check, a trigger -- and has not committed yet.
- TX2 writes an event for Ticket-B. The database assigns it position 11. TX2 commits immediately.
- The projection runs. It queries the Event Store for events after position 9. It sees position 11 -- TX2's event is visible. But position 10 is invisible. TX1 has not committed. The row exists but is locked inside an uncommitted transaction.
- The projection processes event 11 and advances its position to 11.
- TX1 finally commits. Event 10 is now visible. But the projection already moved past it. It will never go back.
Event 10 is lost. Silently. Your read model is permanently inconsistent with your Event Store. The projection skipped an event because it was not visible at the exact moment the query ran. All of your SELECTs against that read model are now broken – and they will stay broken.
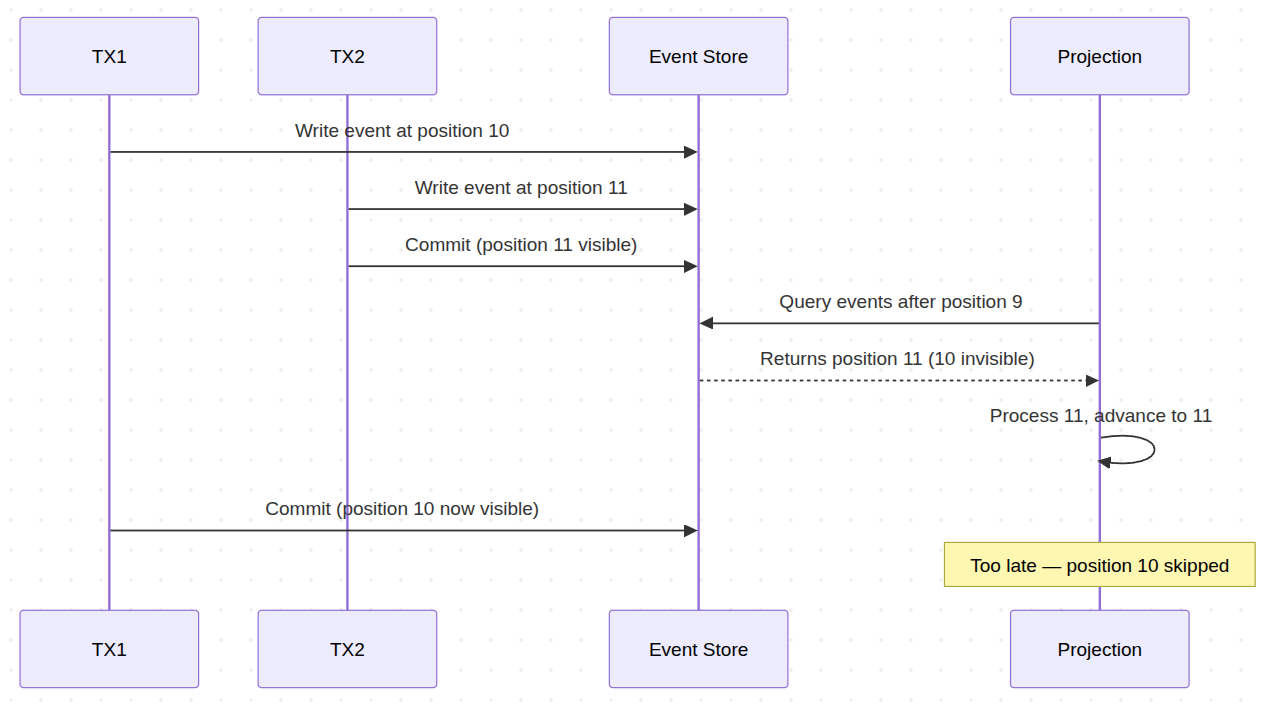
Under concurrent writes, this is guaranteed to happen. The only question is how your system handles it when it does.
Gap Detection
Three approaches exist in the ecosystem. Two are common. One actually solves the problem fundamentally.
No Gap Detection
Ignore it. The projection reads visible events, advances its position, moves on. Invisible events are permanently skipped. Silent data loss. Your read model diverges from the Event Store with no error, no log entry, nothing. Teams discover it months later when a customer reports a wrong balance -- and the only solution is to rebuild the projection from scratch.
This often happens from lack of awareness about the problem focusing only on the happy path, and you would be suprised how many event sourcing libraries have this as their default behavior.
Time-Based Blocking
When the projection detects a gap, it stops and waits until the gap fills or a timeout expires. This blocks all progress – every event behind the gap waits, even from unrelated events.
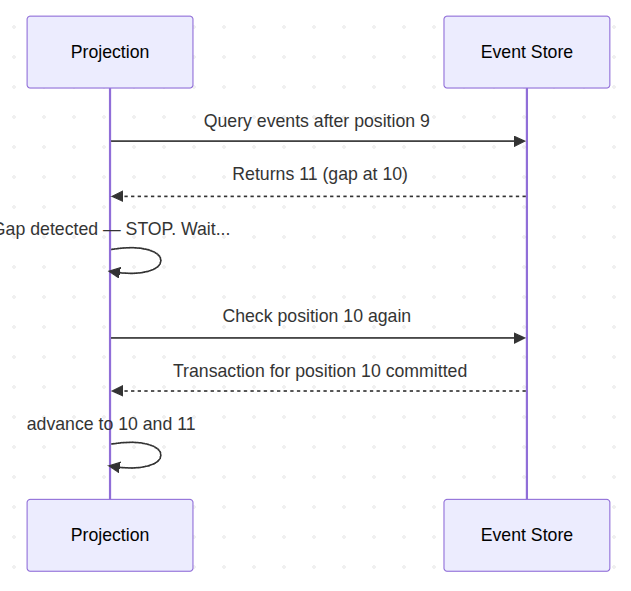
Time-Based blocking can be implemented using two approaches generic on the code level with a time delay, or on database feature based on transaction visibility. This feature may however becomes problematic in high concurrency scenarios, as each Projection will be waiting for the gaps to fill - even if waiting for Events which are not even relevant to the projection.
Blocking is stream-wide, not handler-aware. A Ticket projection will block on a slow Order transaction it doesn't even subscribe to.
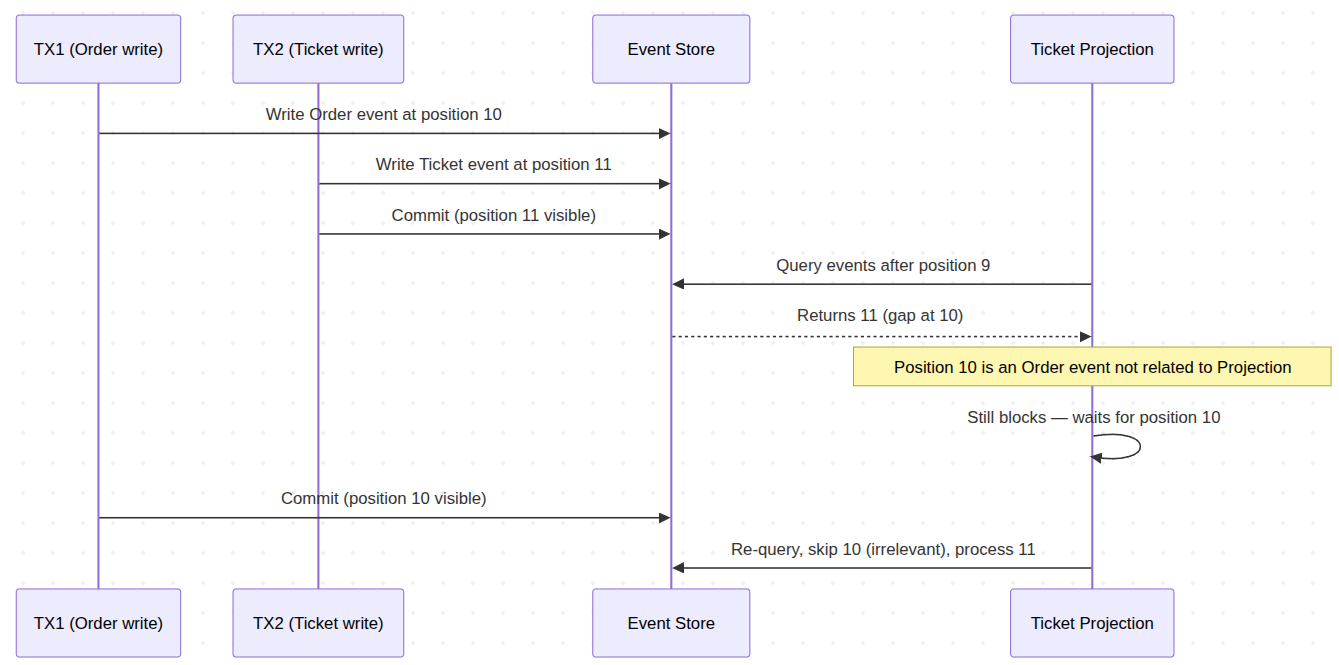
Time-based blocking waits even for events the projection doesn't subscribe to — a slow Order transaction stalls projections which subscribe do different events
Database-Level Write Locking
A different angle on the same problem: instead of detecting gaps after they happen, prevent them from ever existing. Use a database-wide advisory lock so only one transaction can write to the Event Store at a time.
If only one transaction writes at a time, gaps are structurally impossible. The auto-increment column advances contiguously. Projections never need to detect anything – they just read in order.
This works correctly. Gaps cannot happen, projections never need to detect anything, no special infrastructure is required.
With this approach each transaction has to wait for another to finish - and with more load, more transactions will be hanging. We basically solved down our write side, because of the problems on the read side. The worst part if we've traded-off failure isolation, as right now if one of those transaction will dead-lock, we will basically bring down all the other.
Track-Based Non-Blocking (Ecotone's Approach)
Ecotone records the gap and keeps making progress.
When the projection sees position 11 but not position 10, it processes event 11 and stores its position in a compact format:
"11:10"
Position format: "current position : known gaps" – the projection is at position 11 with a recorded gap at 10
This means: "I have processed up to position 11, but position 10 is a known gap." On the next run, the projection checks its gap list first. If TX1 has committed and event 10 is now visible, it processes event 10 and removes it from the gap list. If still missing, the gap stays and the projection continues processing new events.
Multiple concurrent gaps are tracked as a comma-separated list:
"15:10,12,14"
Multiple gaps tracked simultaneously – the projection is at position 15 with gaps at 10, 12, and 14
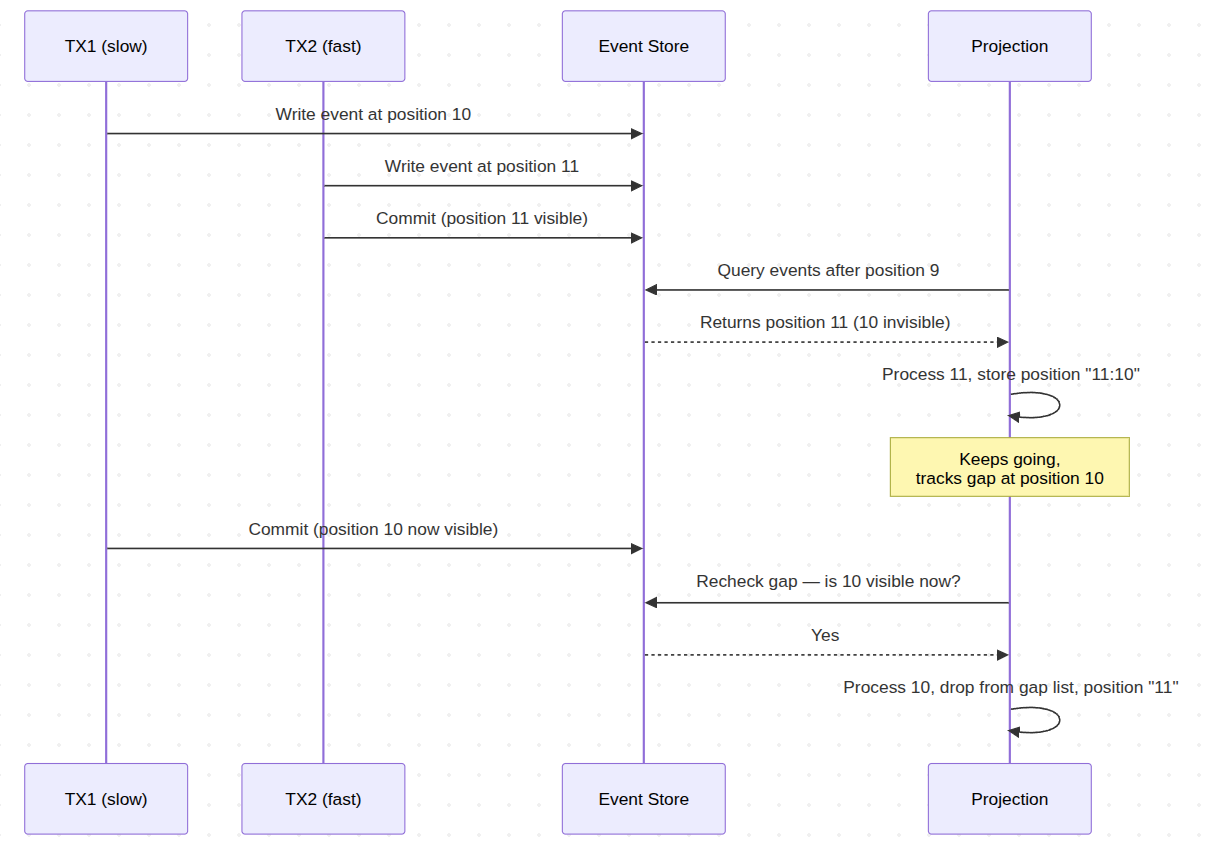
The projection never blocks. It makes continuous forward progress on available events while maintaining positions to revisit. Gaps resolve naturally as slow transactions commit – in practice, within milliseconds.
Gap Cleanup
Not every gap will be filled. A rolled-back transaction leaves a permanently empty position. Ecotone cleans up stale gaps with two strategies:
- Offset-based cleanup: gaps more than N positions behind the current position are removed. If your projection is at position 10,000, a gap at position 50 is not a pending transaction -- it is a permanent hole.
- Timeout-based cleanup: gaps older than a configured threshold are removed. A gap that has existed for minutes is not a slow transaction. It is a rollback.
Both strategies keep the gap list bounded, even under sustained concurrent writes.
Partitioned Projections
Gap detection is a workaround for a problem caused by interleaving. Events from different aggregates share one global sequence – and concurrent writes across them are what creates the gaps in the first place. Within a single aggregate, gaps cannot happen at all: the Event Store's optimistic locking guarantees strict version ordering. So we can sidestep the entire problem by tracking each aggregate independently.
To see why this is possible, look at what is actually inside the stream. Every event carries two identifiers beyond its global sequence number: an aggregate_id (which aggregate it belongs to) and an aggregate_version (its position within that aggregate's own history). The global sequence is shared across everything, but the (aggregate_id, version) pairs form natural partitions inside the same stream.
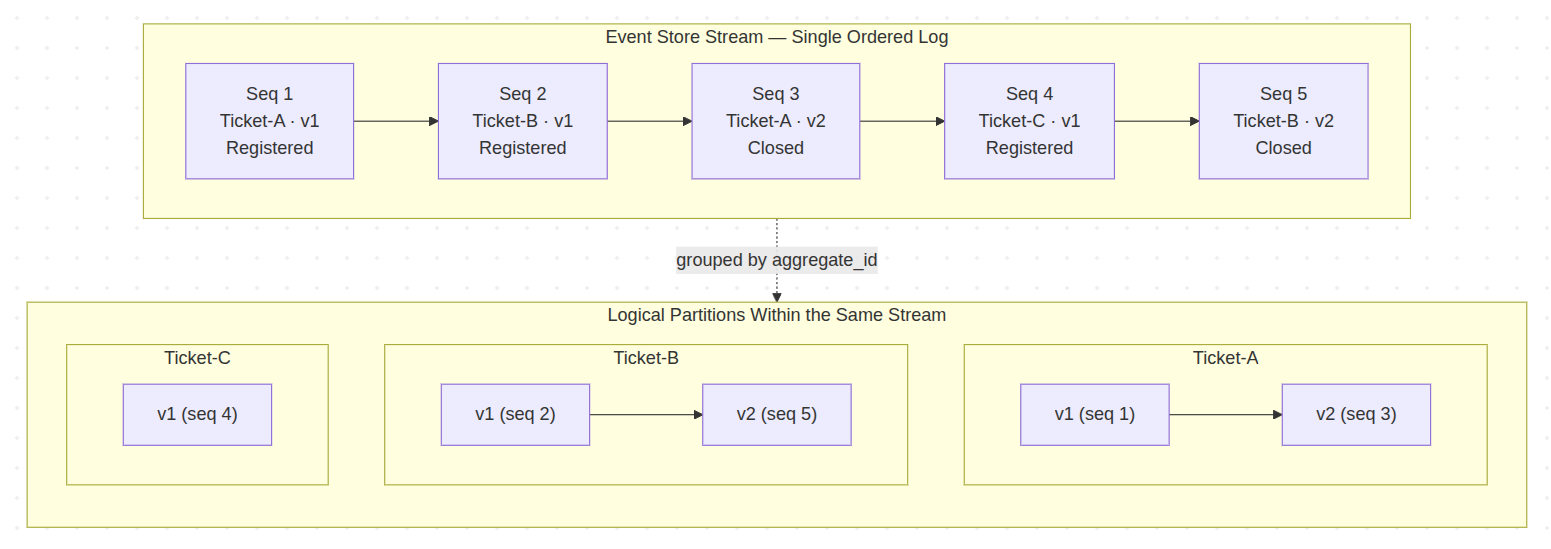
A partitioned projection stops tracking the global sequence number. Instead, it keeps one position per aggregate_id – the aggregate_version of the last event it processed for that aggregate. There is no shared cursor for workers to fight over.
#[Partitioned]
#[ProjectionV2('ticket_list')]
#[FromAggregateStream(Ticket::class)]
class TicketListProjection
{
public function __construct(private Connection $connection) {}
#[EventHandler]
public function onTicketRegistered(TicketWasRegistered $event): void
{
$this->connection->insert('ticket_list', [
'ticket_id' => $event->ticketId,
'ticket_type' => $event->type,
'status' => 'open',
]);
}
#[EventHandler]
public function onTicketClosed(TicketWasClosed $event): void
{
$this->connection->update(
'ticket_list',
['status' => 'closed'],
['ticket_id' => $event->ticketId]
);
}
}
In Ecotone Framework adding #[Partitioned] describes that projection should track position per aggregate id – each aggregate instance gets its own position tracker
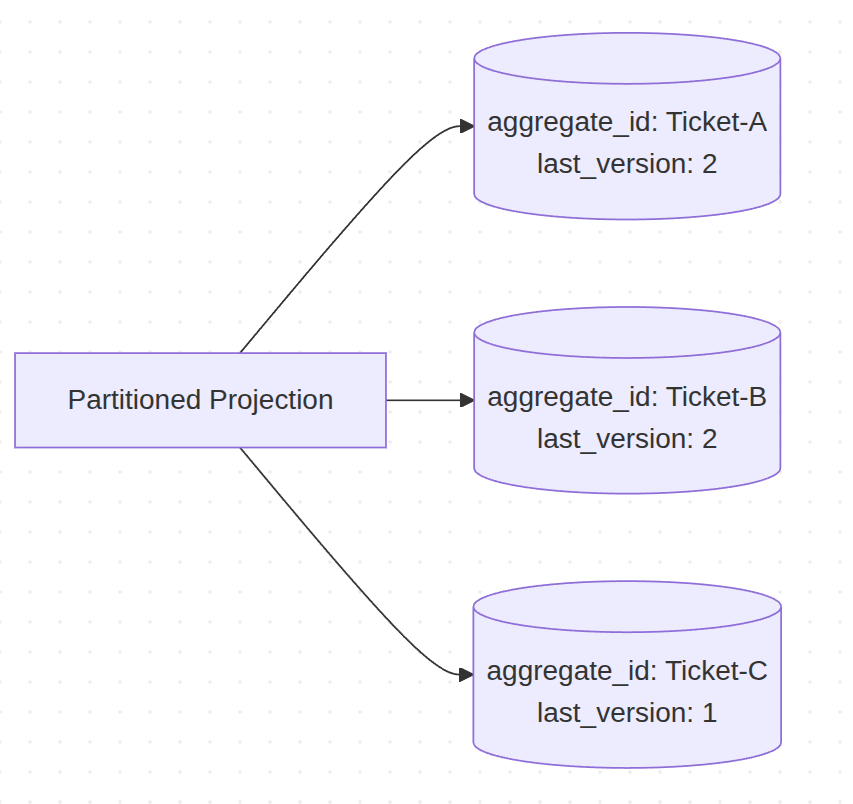
Here is the key insight: partitioned projections do not need gap detection at all. There are no concurrent writes to the same aggregate -- the Event Store prevents it at the database level. Two transactions writing to the same aggregate? One fails and has to retry - meaning no gaps.
Gaps only occur when events from different aggregates interleave in a global stream. Within a partition, the sequence is always strictly ordered: version 1, version 2, version 3. The entire class of problems that gap detection solves simply does not exist here.
Filtering Power
Eliminating gaps does not only simplify correctness -- it unlocks an optimization that global projections fundamentally cannot use: filtering events at the database.
A global projection has to fetch every event in the stream, even ones its handlers do not care about. The reason is gap detection. Filter at the database query -- "only give me TicketRegistered and TicketClosed" -- and the projection loses the ability to tell gaps apart from filtered-out events. A missing sequence number could be a slow transaction creating a real gap to track, or it could be an OrderShipped event that was correctly excluded by the filter. The two cases are indistinguishable. So global projections fetch the full firehose and discard the irrelevant events at runtime.
Partitioned projections do not need to detect gaps. Versions within an aggregate are strictly ordered -- there is nothing to detect. That removes the constraint, and Ecotone uses it automatically: it inspects the projection's #[EventHandler] methods, derives the subscribed event types, and pushes that filter down into the Event Store query.
-- Global projection: must fetch every event
SELECT * FROM events WHERE sequence > :last_position;
-- Partitioned projection: filter to only subscribed events
SELECT * FROM events
WHERE sequence > :last_position
AND event_type IN ('TicketRegistered', 'TicketClosed');
Ecotone derives the event_type filter from the projection's #[EventHandler] declarations. The database does the filtering, not PHP.
The savings compound at scale. Take a 50 million event stream where Ticket events represent 5% of total volume. Twenty times less network I/O. Twenty times less deserialization. Twenty times less memory churn. A backfill that used to read 50 million rows from the database now reads 2.5 million – before any worker parallelism is even applied. On a stream where the projection's events are 1% of total volume, the gap is a hundredfold.
Scaling Through Partitioning
Per-aggregate position tracking does more than eliminate gaps -- it unlocks horizontal scaling.
A global projection has exactly one position for the entire stream. Adding more workers does not help: only one worker can advance the cursor at a time. Extra workers create lock contention, not throughput.
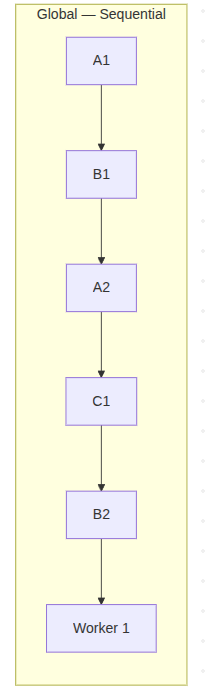
A partitioned projection has one position per aggregate. Different workers can hold different aggregates simultaneously, with no shared state between them. Worker 1 advances Ticket-A's position. Worker 2 advances Ticket-B's. They never touch each other's data.
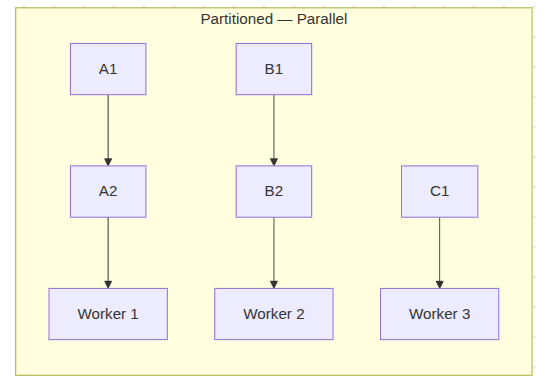
Throughput scales with worker count – up to the number of distinct aggregates being written to. A system with thousands of active tickets and 8 workers will see roughly 8x the projection throughput of a single-worker setup. Add more workers, process more partitions in parallel.
This matters most when you deploy a new projection against a stream that already has years of history. Backfilling a fresh read model from scratch is the worst-case scaling scenario: there is no live trickle to keep up with -- there is a mountain of historical events waiting to be processed before the projection is usable. With a global projection, that mountain is climbed by a single worker, sequentially, regardless of how much hardware you throw at it. A stream with hundreds of millions of events can take days to catch up.
With partitioning, you can spin up dozens of workers to chew through different aggregates in parallel. Rebuild process that took days can take hours. the one that hours can take minutes. The same property that makes live processing scale also collapses backfill time – which is often the difference between "we can deploy this projection on Monday" and "we need a maintenance window and a four-day catch-up plan."
High-Performance Projections with Flush State
Even with partitioning and filtering, rebuilding a read model from millions of historical events is expensive if you commit on every single event. Each commit is a database round-trip, a transaction boundary, index updates. A system processing 500K events per hour can hit memory pressure fast if each event triggers its own write.
The solution: accumulate state in memory across a batch and persist it once.
#[Partitioned]
#[ProjectionV2('ticket_list')]
#[FromAggregateStream(Ticket::class)]
#[ProjectionExecution(eventLoadingBatchSize: 1000)]
class TicketListProjection
{
public function __construct(private Connection $connection) {}
#[EventHandler]
public function onTicketRegistered(
TicketWasRegistered $event,
#[ProjectionState] array $ticket = []
): array {
return [
'id' => $event->ticketId,
'status' => 'open',
'version' => 1,
];
}
#[EventHandler]
public function onTicketClosed(
TicketWasClosed $event,
#[ProjectionState] array $ticket = []
): array {
$ticket['status'] = 'closed';
$ticket['version'] = $ticket['version'] + 1;
return $ticket;
}
#[ProjectionFlush]
public function flush(#[ProjectionState] array $ticket = []): void
{
if (empty($ticket)) {
return;
}
if ($ticket['version'] === 1) {
$this->connection->insert('ticket_list', [
'ticket_id' => $ticket['id'],
'status' => $ticket['status'],
'version' => $ticket['version'],
]);
} else {
$this->connection->update(
'ticket_list',
['status' => $ticket['status'], 'version' => $ticket['version']],
['ticket_id' => $ticket['id']]
);
}
}
}
Per-partition state: each ticket's events accumulate into a single ticket record (id, status, version). #[ProjectionFlush] persists once per batch -- version 1 means a freshly registered ticket (INSERT), anything higher is an existing ticket being updated.
Because the projection is #[Partitioned], the #[ProjectionState] is per aggregate -- one ticket's state, not a global aggregator. Each #[EventHandler] receives the current ticket and returns its updated form. No database writes happen during event handling. After each batch, Ecotone calls #[ProjectionFlush] once per partition with the final accumulated ticket state -- a single INSERT or UPDATE per ticket.
For a ticket that goes through registration, three status changes, and closure -- five events -- you get one database write instead of five. Across a backfill of millions of tickets, that compounds.
Combined with partitioning: parallel workers, each driving their own aggregate's lifecycle through memory and persisting only the final state per batch.
Use the Database Only When Needed
A traditional global projection runs on a schedule. Every few seconds it polls: "any new events?" Most of the time the answer is no, and the query was wasted -- a scan over an empty range, a position read, a position write. Multiply that across dozens of projections, all polling continuously, and the database is being pushed just to confirm there is nothing to do.
Partitioned projections in Ecotone work differently. A projection is triggered by activity, not by a clock -- and only on the partitions that actually had activity.
Synchronous (inline) projections run as part of the same transaction that persists the event. The aggregate writes its event, the projection updates the read model, both commit together -- no polling worker, no separate process, no idle queries. And because each aggregate has its own partition, an inline projection on Ticket-A does not block writes happening on Ticket-B at the same moment. Other aggregates flow freely.
Asynchronous partitioned projections decouple the projection from the write path. The aggregate appends its event and returns immediately. Ecotone delivers that event to the projection through its messaging infrastructure, once the event happens. Two consequences:
- Speed: the write transaction does not wait for the projection. Append latency stays low even if the projection is slow, behind, or temporarily down.
- Reliability: a bug in the projection does not poison the event append. The event is safely persisted regardless of what the projection does with it afterwards. You can fix the projection, replay it, and recover -- the source of truth was never at risk.
But in context of scalability - the most importantly, the projection is woken by the event itself.

On append, the Event Store publishes a trigger to the channel. The channel wakes the projection, which then pulls the events for its partition straight from the Event Store. The database is queried only when there is actually something to fetch – never on a timer.
This is the difference between "ten projections each polling the database every second" and "ten projections that only run when there is something to do." On a system with bursty traffic, the idle cost drops to zero.
The only Events that actually wake up the Projection to pull events from Event Store, are actually the ones that projection subscribes to. A projection that handles two event types out of ten across the system, is woken exactly when those two arrive – never for the other eight. Dispatch is driven by the projection's #[EventHandler] declarations, not by a generic "any event" trigger.
The guarantee composes: a projection's database is touched only when one of its subscribed events is actually appended. No subscribed events for an hour? No database queries from that projection for an hour. The projection sits at zero cost until there is real work to do.
Skipping Deserialization
Every event handler that takes a typed event class -- TicketWasRegistered $event – triggers a deserialization step: Ecotone reads the JSON payload from the Event Store and hydrates a PHP object. For a single event, the cost is invisible. For a backfill of fifty million events, it is one of the largest CPU expenses outside of the database itself.
Ecotone supports an alternative: identify the event by its name in the #[EventHandler] attribute, type-hint the parameter as array, and Ecotone hands the raw payload straight to the handler – no class, no reflection, no hydration.
#[Partitioned]
#[ProjectionV2('ticket_list')]
#[FromAggregateStream(Ticket::class)]
class TicketListProjection
{
public function __construct(private Connection $connection) {}
#[EventHandler('ticket.registered')]
public function onTicketRegistered(array $event): void
{
$this->connection->insert('ticket_list', [
'ticket_id' => $event['ticketId'],
'status' => 'open',
'version' => 1,
]);
}
#[EventHandler('ticket.closed')]
public function onTicketClosed(array $event): void
{
$this->connection->update(
'ticket_list',
['status' => 'closed', 'version' => $event['version']],
['ticket_id' => $event['ticketId']]
);
}
}
Events are addressed by their stored name (ticket.registered, ticket.closed) instead of by PHP class. Ecotone delivers the raw associative array straight from the Event Store with no class deserialization step.
There is a second reason this matters beyond throughput: the event class no longer has to exist. If the domain model has moved on – the original TicketWasRegistered class was deleted in a refactor, the aggregate now uses different events – a projection that reads the historical events as arrays will keep working. You do not need to keep dead PHP classes alive just to satisfy a projection. The event name in the Event Store is the only contract that matters.
On a rebuild of tens of millions of events, the deserialization shortcut alone can shave a meaningful slice off total CPU time. Combined with filtering at the database, partitioning across workers, and flush-state batching, it is the last layer of overhead to remove before the projection is bound only by the Event Store's I/O.
Streaming Projections — Bypassing the Database Entirely
That last bound – the Event Store's I/O – is itself a ceiling. Every event read still goes through the database: a query plan, a network round-trip, position updates persisted back to disk. For the vast majority of systems however, the techniques covered above are enough to limit I/O from the Event Store so that it is no longer a bottleneck. However if you want to avoid any extra load on your Database coming from projections, then you need streaming projections.
Streaming projections solve removes database from the read path entirely. In this mode, the projection consumes events from a message broker (Kafka) instead.
#[Streaming('orders_channel')]
#[ProjectionV2('external_orders')]
class ExternalOrdersProjection
{
#[EventHandler]
public function onOrderReceived(
OrderReceived $event
): void {
// Events come from broker, not database
}
}
The #[Streaming] attribute replaces #[FromAggregateStream]. Events are delivered by the broker when they arrive, they are not fetched from the Database Event Store.
Ecotone does not manage position state in the database for streaming projections as that would kill the purpose. In this case Kafka tracks consumer offsets, meaning no extra database calls to persist the last processed position.
Feeding a Streaming Channel from the Event Store
You do not need an external event source. Ecotone provides EventStreamingChannelAdapter -- a bridge that reads from your database Event Store and forwards events to a streaming channel.
#[ServiceContext]
public function eventStoreFeeder(): EventStreamingChannelAdapter
{
return EventStreamingChannelAdapter::create(
streamChannelName: 'product_stream_channel',
endpointId: 'product_stream_feeder',
fromStream: 'product_stream',
);
}
The adapter polls the Event Store and pushes events to the streaming channel. Run it as a background process.
The feeder is the only process that talks to the database. Once events land in the streaming channel, projections subscribe to that channel and are pushed events as they arrive – they never query the Event Store themselves.
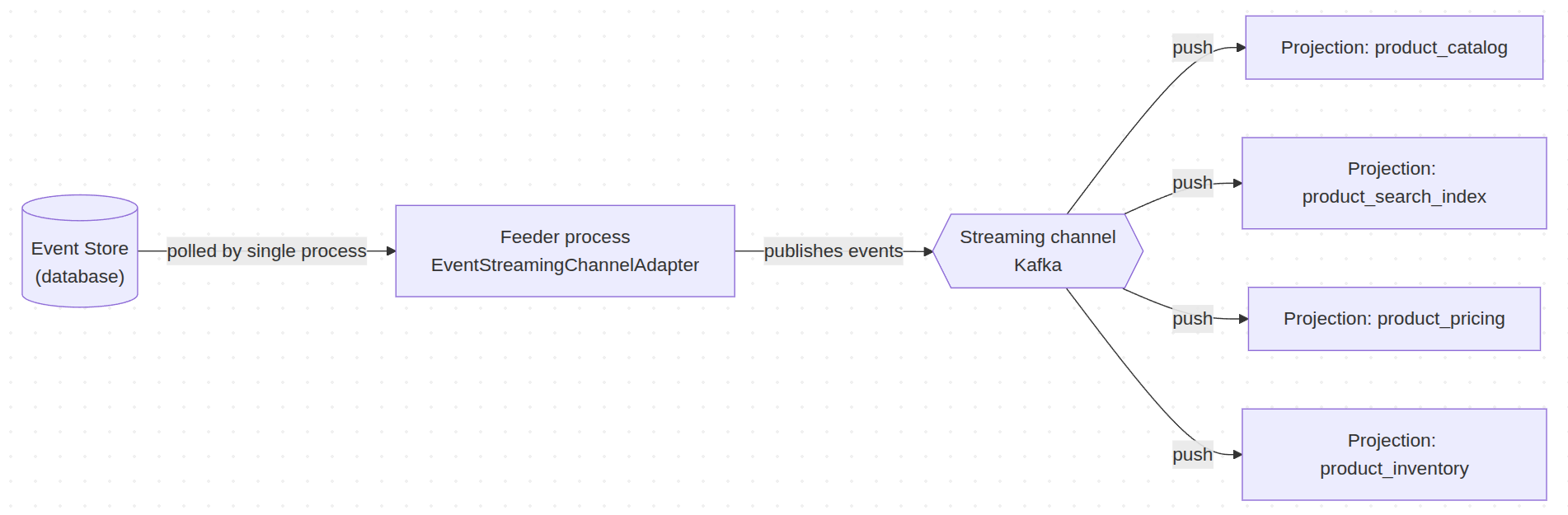
bin/console ecotone:run product_stream_feeder -vvv
# Start any number of streaming projections — each is push-driven by the channel
bin/console ecotone:run product_catalog -vvv
bin/console ecotone:run product_search_index -vvv
bin/console ecotone:run product_pricing -vvv
bin/console ecotone:run product_inventory -vvv
For the overwhelming majority of systems, you will never need to reach this far. Partitioning, filtering, flush state, and event-driven dispatch handle the workloads that real applications actually encounter.
The value of having streaming as an option is not that you will use it tomorrow – it is that the foundation you are building today does not have to be torn down if you ever do. Same projection class, same event handlers, same partitioned read model: a single #[Streaming] attribute is the only thing that changes when you decide to swap the database for Kafka. No rewrites. No new contracts. No migration plan. One annotation, a different transport underneath.
What Comes Next
We have solved correctness with gap detection, scaling with partitioning, batching with flush state, idle cost with event-driven dispatch, CPU with array handlers, and database I/O with streaming. The projection itself now performs.
But projections do not live alone. The moment a read model is updated, other parts of the system want to know when it changes and what changed -- and that raises three uncomfortable questions:
- Subscribers see stale state. A consumer reacts to a domain event --
MoneyWasAddedfires, the consumer queries the read model for the new balance -- and gets the old one, because the projection has not finished updating yet. Does this mean every projection that anyone reads from has to run synchronously, blocking the write path on every read model update? - External teams want to build on your events. Reporting, compliance, analytics -- another team wants to subscribe to the events you publish and build their own read models from them. Those events instantly become a contract. Every renamed field, restructured aggregate, or split event breaks a downstream service. Are you doomed to either freeze your domain model forever, or coordinate every event change across half the company?
- Subscribers want more than "what changed". Raw domain events tell you that something happened, not what the resulting state now is. A notification service that wants to push the user's new balance does not just need
MoneyWasAdded-- it needs the computed balance. So you start enriching every event with state -- balance, status, totals -- inflating each one with whatever any consumer might ever want. Are we really forced to end up with Events describing snapshots of our system?
Each of these has a clean answer that does not require synchronous projections, frozen contracts, or bloated event payloads. And in next article we will look deep into how actually Projections can help us solve these problems, rather than being the cause of them.