
Async Failure Recovery: Queue vs Streaming Channel Strategies
Master failure recovery for queues and streams. Learn when each strategy works and why. Build message-driven systems that self-heal.

In this article we will discuss building asynchronous Systems in depth.
We will tackle why a recovery strategy that works perfectly for queue-based workflows may break for event streaming platforms. We will see exactly when resending messages causes duplicate processing, and when it’s actually your best move. And learn why defining channel’s purpose isn’t just good practice — it’s the difference between a system that can self-heal and one that requires manual intervention and constant attention.
We will know what and why given failure recovery strategy exists, and which one works in specific scenarios, and more importantly, why they fail when misapplied. And to build this mental model, we will first start by understanding the core differences between Message Channel types.
Queue Channel

The most common Messaging Architecture is based on Queue Channels. Queues collects Messages, and in solutions like RabbitMQ provides them for consumption in same order they have been published. Messages in Queues have destructive nature, meaning if Message is consumed successfully, it will be removed from the Queue.
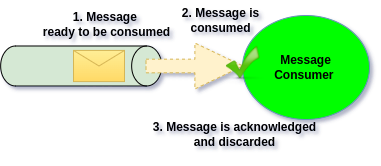
Queue is a shared Channel from which multiple Message Consumers can consume. Scaling up Messages Consumers for same Queue, will parallel the work to speed up message consumption. Multiple Consumers running against same Queue, is so called Competitive Consumer pattern:
What’s worth noting here is that with this architecture there is no limit to scaling. If our infrastructure can handle rolling out 100 Message Consumers for the same queue, we can simply do it — the workload will be parallelized across all of those consumers.
In case of Queues we don’t really want to depend on the order of Message consumption, as otherwise we would have to bind to only single Consumers and disallow scaling completely. Preserving order is often stated to be required part of the system, however preserving order comes with cost and can actually be considered for subset of features rather than applied globally. We will discuss message order a bit later.
Event Streaming Channel
The other Channel type which we may face is Event Streaming Channel.
We can discuss it in context of Kafka implementation, as it’s the most used technology in context of Event Streaming Channels — also called Topics.
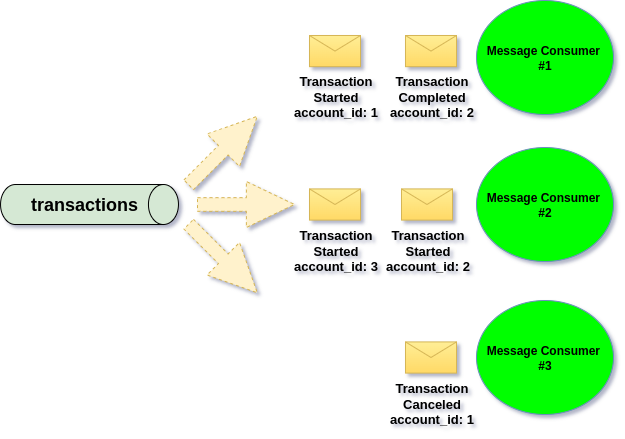
Event Streaming Channel (Topic) is broken into partitions, which you can imagine as smaller lanes (sub-channels). All messages with the same partition key always go into the same lane, never anywhere else:
Each partition can have only one active consumer, which keeps message order inside that partition. If we start more consumers than partitions, the extra ones stay idle because they have no partition to read from.This means consumer scaling is limited by the number of partitions, unlike Queues where scaling is unrestricted.
With two partitions, we can run at most two consumers.
Partition count should be chosen when creating the topic, because adding partitions later does not move existing messages. Meaning Messages which landed in partition “X”, may now be assigned partition “Y”, which would break the order.
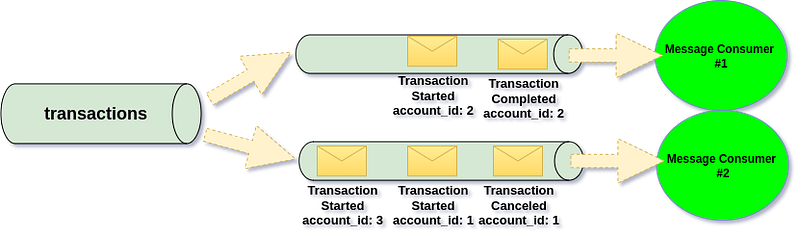
In Kafka-style Event Streaming Channels, messages are not removed after consumption. They remain in the channel and are cleaned only based on retention settings defined on the broker.
This means consuming a message does not delete it — consumption simply updates the consumer’s committed position. This is the core design difference between Queues and Event Streaming Channels.
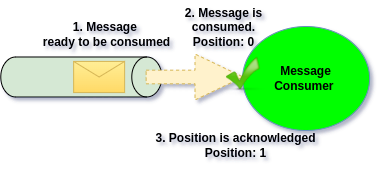
To build correct mental model for this, we need to be more precise here. Event Stream Channels have partitions (sub-channels), therefore what actually happens when we commit position, is that we are committing position within the partition (specific sub-channel):
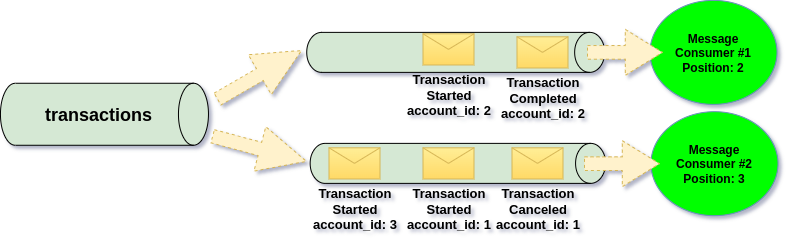
Since messages are not removed after consumption, multiple applications can read the same channel independently.
Each application keeps its own tracking state, identified by a Message Group Name — essentially the name of its consumer group.
A Message Group lets several consumers share the same tracking, ensuring each message is processed once per group. If you create multiple groups, every group will consume the same message independently.
RabbitMQ Queues don’t have this concept, so they effectively behave as one Message Group.
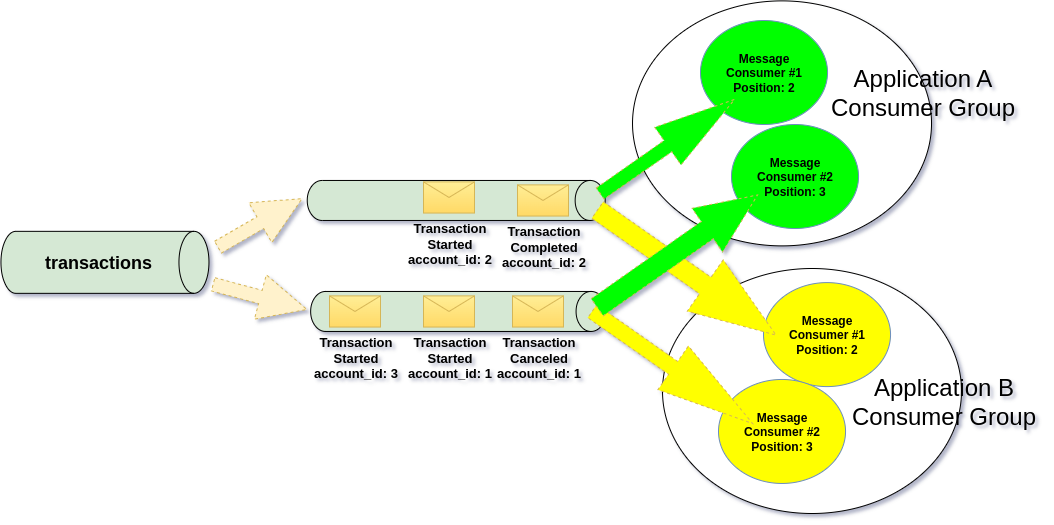
Using multiple Message Groups turns the channel into a shared stream, and this changes how we can process and recover messages, as narrows the options for handling failures.
That’s why understanding the channel’s intended purpose matters — far beyond simply choosing Queue or Streaming Channel.
I talk about RabbitMQ as a Queue and Kafka as a Stream, but both platforms now blur this line.
RabbitMQ supports streaming, and Kafka is adding queue-style channels.
Because of that, it’s crucial to know how these channel types differ so we can pick the right one for the job.
So far, we’ve focused on what Message Channels can do — their technical capabilities, but just as important is how we plan to use them — their actual purpose.
Read and Write side of the System
There are two ways of looking at the system:
- Write side — Protect invariants, triggers side effects, changes our internal models.
- Read side — Serves data for reading, which is built from what happened on the “write side”
Whatever are our Message Channel is related to Read or Write side, will help us understand how we can behave in context of failures.
“Write side” is responsible for our business operations, therefore stopping it due to failure means we are stopping the Business from working.
On other hand “Read side” is concerned with building data for reading, from what happened on the “write side”. Even if it’s stopped, it doesn’t mean that the business is stopped, it means however that our end-users may be making decisions based on stale view.
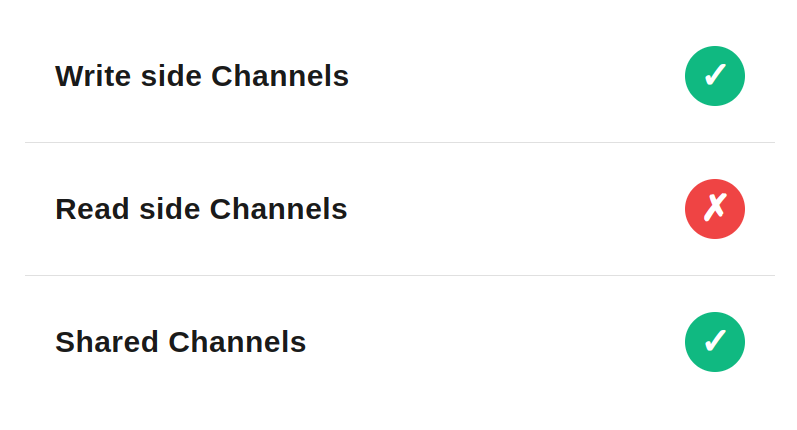
Write side
If our Message Channel was created with purpose of handling write side, it means we care about immediate reaction to business events as they occur. Each event represents a trigger that initiates specific business workflow or actions.
Here the goal is to complete the action, not to preserve strict ordering. For example, we shouldn’t stop future payments for an account just because one payment can’t be processed right now. Business continuity matters more than enforcing technical order.
Use Cases:
- Triggering business actions (e.g. Welcome email when user registers, Payment processing when order is placed, scheduling future actions)
- Workflow orchestration (e.g. Credit Card approval process, Order processing, data manipulation ETL)
- External Integration Triggers (e.g. Setting up account in 3rd party, Calling another Service to update data, or perform another action)
Query side
If our Message Channel was created with purpose of query side, meaning preparing data to read, then we will be interested in the complete timeline of events to reconstruct current state, build derived views, synchronize complete state of system.
The purpose here is to build a view model that represents past system activity. Failures are acceptable because they don’t interrupt real business actions; they only make the view outdated. And since this data can be naturally eventually consistent, a blockage simply extends that delay.
Use Cases:
- Building read models/projections from event history (e.g., customer profile from all their interactions)
- System synchronization / data replication using complete event streams
- Analytics dashboards that aggregate historical patterns
Shared Channel
A shared channel means the same message can be consumed multiple times, for example by different applications. In practice, this is achieved by using multiple Message Groups.
When multiple Message Groups consume from the same channel, failure handling becomes more complex.
If Application X can’t process a message, Application Y might still succeed.
Resending the failed message back to the channel could cause Application Y to process it twice. Therefore it’s important to define whatever given channel is meant to be shared, as it will require different recovery strategies.
Kafka-style Event Streaming Channels can act as shared channels because they support multiple Message Groups. A channel becomes shared only when more than one group consumes from it.
In contrast, RabbitMQ Queue Channels cannot be shared, as they always operate with a single Message Group. However RabbitMQ Stream Channels can be shared.
Failure Recover Strategies
Kafka and RabbitMQ offer strong messaging features, but it’s our responsibility to choose and implement recovery correctly on top of that.
If we choose poorly — or ignore error handling — we will discover the consequences at the worst possible time: in production.
Therefore when failure happens, we need to do something with failed Message, we need to decide what action will we take, and for this we do have different failure recovery strategies, which can be applied in specific use cases.

We will now discover what failure recovery strategies we have at hand, we will also see how they have been actually implemented in PHP framework that I am author of — Ecotone.
Release Failure Strategy
When failure happens, we need to do something with failed Message, therefore we need to decide what action will we take.
The simplest solution which we can apply is to “release” the Message for re-consumption.
This option preserves Message and the order (sequence), however our processing becomes blocked till the moment Failed Message is consumed successfully.
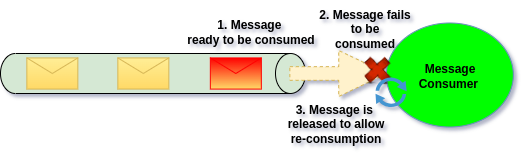
Use Case
Message release allows us to free-up the Message and re-consume it again, meaning Message is preserved even it has failed. This however comes with huge cost, as in case of unrecoverable errors, we will block processing completely.
In case of Release Failed Strategy, the scope of blocking will differ between Kafka and RabbitMQ. However in both ways System becomes blocked to some degree and will continuously waste resources on handling Message that will always fail.
This recovery strategy works in all scenarios, making it a good last resort when everything else has failed. It won’t introduce unwanted side effects.
However, relying on it alone is not recommended, as it can block the business from operating.
Real life implementation
Ecotone exposes release strategy as “final failure strategy”.
Final failure strategies run only when no other strategy does apply or when no other recovery stategy have succeeded.
With RabbitMQ, releasing a message requeues it for future processing.
With Kafka, releasing resets the consumer offset so the same message is read again on the next poll.
/** RabbitMQ Consumer example */
#[RabbitConsumer(
endpointId: 'transaction_handler',
queueName: 'transactions',
/** Requeue the Message to re-fetch it again */
finalFailureStrategy: FinalFailureStrategy::RELEASE
)]
public function processTransactionEvent(TransactionEvent $event): void
{
// Handle Transaction Event
}
/** Kafka Consumer example */
#[KafkaConsumer(
endpointId: 'transaction_handler',
topics: 'transactions',
/** Keep current offset to re-read the Message */
finalFailureStrategy: FinalFailureStrategy::RELEASE
)]
public function processTransactionEvent(TransactionEvent $event): void
{
// Handle Transaction Event
}You can read more about final failure strategies here.
Ignore Failure Strategy
We can also ignore the failed Message in order to unblock the processing.
By ignoring failed Message, we will simply skip it over, meaning that Message will be lost. Therefore this option is only feasible for non-critical Messages which can be lost.
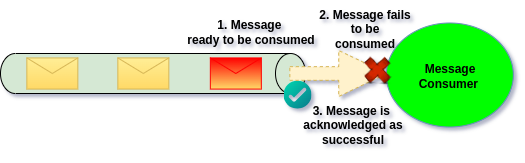
Use Case
The use case for ignoring Message is really limited and should only be considered if we are able to simply accept the fact that Message will be lost. We may want to use ignoring strategy for “Write side” — for example while tracking high volume of data, where losing few messages will not affect final results (e.g. tracking temperature changes).
However for building Read side, where we may be building views from incoming Messages, skipping over Messages will cause generated data to be incompletele or simply incorrect. Therefore it should be used with “Read side” Channels.
Real life implementation
Just the same as Release strategy, Ignore strategy should rather be treated as last resort and this is how Ecotone implements it.
We will see a bit later how we can combine different strategies together, however what is important now, is that it’s actually final strategy, when any other strategy does not apply or any other strategy has failed.
This can be implemented by simply acknowledging the Message and moving forward, therefore from technical side it can work the same as succesfull processing.
/** RabbitMQ Consumer example */
#[RabbitConsumer(
endpointId: 'transaction_handler',
queueName: 'transactions',
/** Discarding Messages after failure */
finalFailureStrategy: FinalFailureStrategy::IGNORE
)]
public function processTransactionEvent(TransactionEvent $event): void
{
// Handle Transaction Event
}
/** Kafka Consumer example */
#[KafkaConsumer(
endpointId: 'transaction_handler',
topics: 'transactions',
/** Discarding Messages after failure */
finalFailureStrategy: FinalFailureStrategy::IGNORE
)]
public function processTransactionEvent(TransactionEvent $event): void
{
// Handle Transaction Event
}You can read more about final failure strategies here.
Deduplication (Idempotency)
With idempotency, a message that was already processed will be ignored if it appears again.
This protects us from duplicates caused by app failures or broker hiccups.
That’s why idempotency must be part of every Message Broker integration, regardless of which recovery strategy we use.
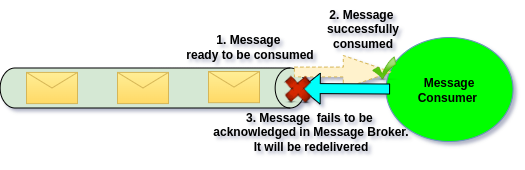
Use case
There are no limits in context of using idempotency, in general we should strive to achieve it no matter if we are dealing with “write” / “read” or shared Channels. If we want to ensure no Messages will be handled twice, this is our way to do it.
There are different ways to achieve deduplication, depending on the situation:
1. If we call an external service (e.g., a payment provider), it may support idempotency keys.
2. In some cases the application itself can ignore repeated actions (e.g., if a customer is already blocked, skip blocking again).
3. The final option is deduplication at the Message Framework level
Point one and two have to be implemented per feature, and will be specific to actual solution we build. However third option is feature agnostic and is more of architecture level solution, which can be applied to different features, and this one we will actually discuss now.
Real life implementation
All messages should include an identifier so we can uniquely recognize them. Message Brokers do not guarantee this, so developers must implement it themselves. Once a message is identifiable, its ID can be used for deduplication.
In Ecotone, internal messages automatically receive a Message ID, which can be used for this purpose. For Messages coming from outside however, a stable and meaningful ID may not exist, so a custom deduplication key may be required.
By default Ecotone will deduplicate by MessageId, however as we can see above, we can customize this process the way we want. Ensuring that even if the Message does have any Message Id, we still can do deduplication based on other means.
For additional deduplication methods, see Ecotone’s documentation.
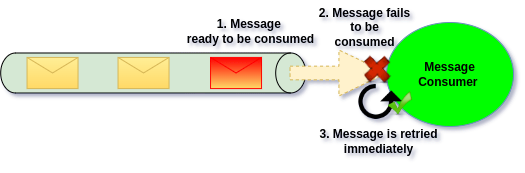
Instant Retry
A common strategy for transient errors is Instant Retry. It ensures when Message has failed, it will be retried immediately up to few times. This way we give ourselves a chance to recover from the failure right away.
Use case
The power of this recover strategy is that we are not losing the order. If message handling fails, we try again right away. This works well for brief problems like lost DB connections or external service timeouts.
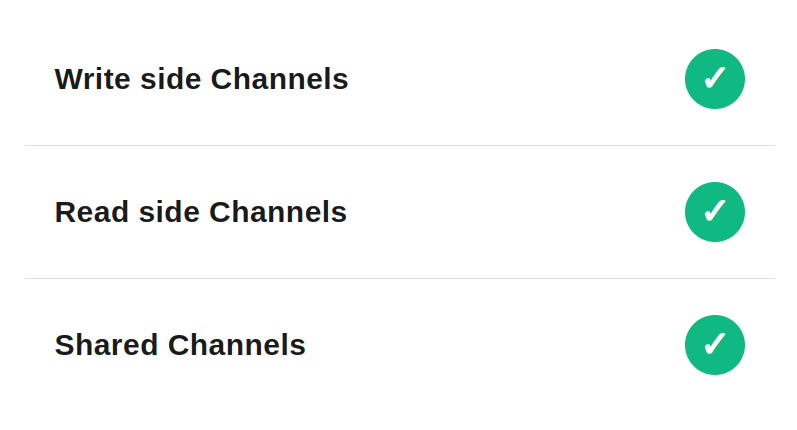
It’s safe to use this strategy with all the approaches for either “write” or “read” and even “shared channels” (as message is not resend back to the Channel).
Real life implementation
To use Instant Retry reliably, each attempt must act like a fresh first attempt. That means removing all prior state — rolling back DB changes, clearing propagation data, etc. With a clean start guaranteed, Instant Retry becomes a safe and reusable strategy.
In case of Ecotone this all happens automatically. Ecotone will ensure that database transaction is rolled back, context headers are clean up, and Message is automatically retried.
/** RabbitMQ Consumer example */
#[InstantRetry(retryTimes: 2, exceptions: [NetworkException::class])]
#[RabbitConsumer(endpointId: 'transaction_handler', queueName: 'transactions')]
public function processTransactionEvent(TransactionEvent $event): void
{
// handle
}
/** Kafka Consumer example */
#[InstantRetry(retryTimes: 2)] // no exceptions given, meaing retry on all exceptions
#[KafkaConsumer(endpointId: 'transaction_handler', topics: 'transactions')]
public function processTransactionEvent(TransactionEvent $event): void
{
// handle
}Read more in Ecotone’s Instant Retry documentation section.
Resend Failure Strategy
When a message can’t be processed, continuous retries will just block the flow, therefore for this we need different way to handle failures.
One of our toolset for doing so is resending the message to the original channel, in order to unblock current message processing:
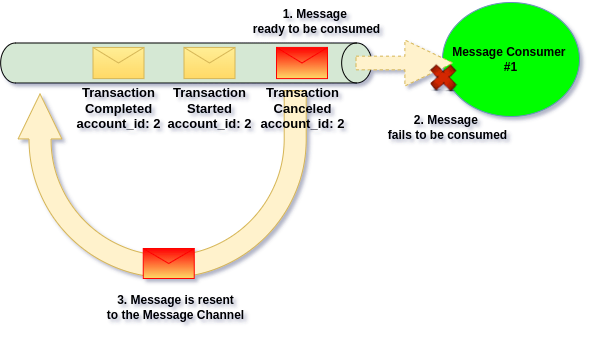
Use case
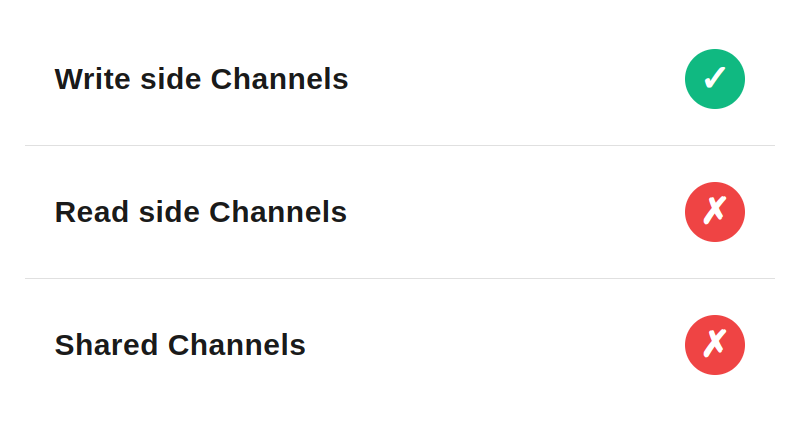
This method fits the write side, where unblocking the flow is more important than the order. It does not work well for the read side however, because it disrupts ordering. It won’t work for shared channels either, as other applications would end up reprocessing a message they may already have handled.
Therefore this failure recovery strategy is most suitable when Channel is under control of Single Message Group and is being used for processing business actions. Then resending the Message won’t affect other parties, and handling the Message out of order may actually lead that Message will recover itself automatically (for example 3rd party API went down for few seconds, we’ve proceessed other Messages and on retry it was successful).
Real life implementation
This strategy works by sending the original message back to the same channel.
It’s crucial to resend the message exactly as it was — including its identifier.
By preserving the original ID, a message that was already processed can be correctly deduplicated.
/** RabbitMQ Consumer example */
#[RabbitConsumer(
endpointId: 'transaction_handler',
queueName: 'transactions',
/** Resend Message to the original Channel */
finalFailureStrategy: FinalFailureStrategy::RESEND
)]
public function processTransactionEvent(TransactionEvent $event): void
{
// Handle Transaction Event
}
/** Kafka Consumer example */
#[KafkaConsumer(
endpointId: 'transaction_handler',
topics: 'transactions',
/** Resend Message to the original Channel */
finalFailureStrategy: FinalFailureStrategy::RESEND
)]
public function processTransactionEvent(TransactionEvent $event): void
{
// Handle Transaction Event
}You can read more about final failure strategies here.
Sending Message to different Channel
We can also send Message to different channel on failure. Moving it from one place to another
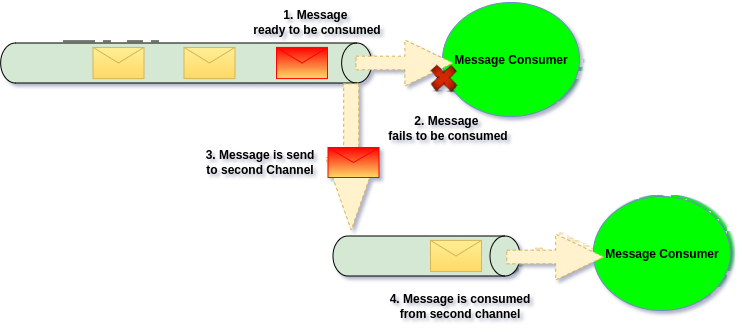
Use case
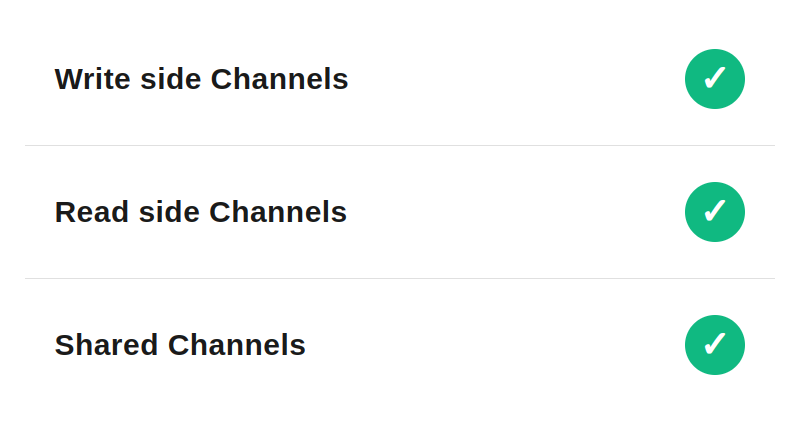
This solution works nicely for all use cases, “write”, “read” and “shared” channels will work well with this. On failure we simply move the Message from one channel to another which can be private to given Message Group (Application).
The down side of this approach is that we can actually end up with another channel being blocked by failures. Therefore the second channel should still apply other failure recovery patterns, simply moving message there is not enough.
This is good approach when the original Channel is shared one, and we would like to move it to exclusive channel. This way the we will be able to use more failure recovery strategy patterns than we would be able to do on the first channel.
Real life implementation
In case of Ecotone we will so called ErrorChannel to which Message should be sent in case of failures. The channel can be of any possible type, we may for example have original Kafka Channel and the second channel as Database Channel.
/** RabbitMQ Consumer example */
#[RabbitConsumer(
endpointId: 'transaction_handler',
queueName: 'transactions',
/** Final failure strategy will be triggered in case sending to Error Channel fails */
finalFailureStrategy: FinalFailureStrategy::RELEASE
)]
#[ErrorChannel('failureChannel')] // define error channel, where to send Message on failure
public function processTransactionEvent(TransactionEvent $event): void
{
// Handle Transaction Event
}
/** Kafka Consumer example */
#[KafkaConsumer(
endpointId: 'transaction_handler',
topics: 'transactions',
/** Final failure strategy will be triggered in case sending to Error Channel fails */
finalFailureStrategy: FinalFailureStrategy::RELEASE
)]
#[ErrorChannel('failureChannel')] // define error channel, where to send Message on failure
public function processTransactionEvent(TransactionEvent $event): void
{
// Handle Transaction Event
}Resending Message with Delay
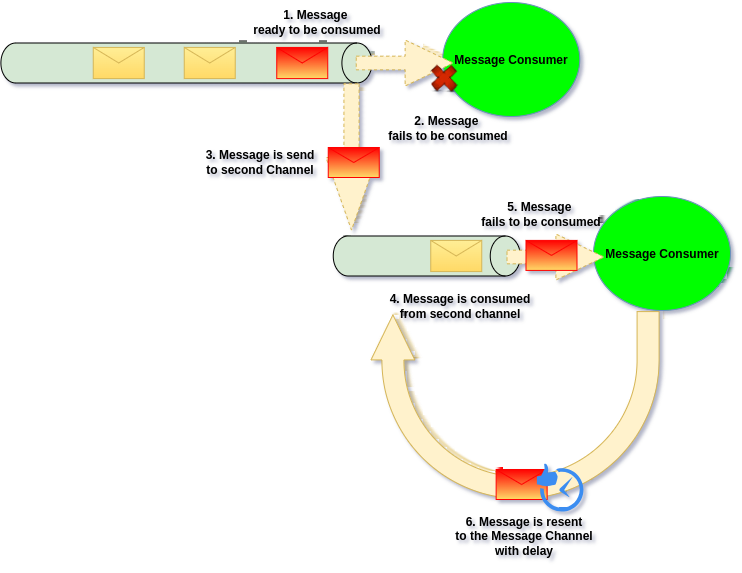
We can also resend Message back with delay, to ensure that Message will re-processed after some time:
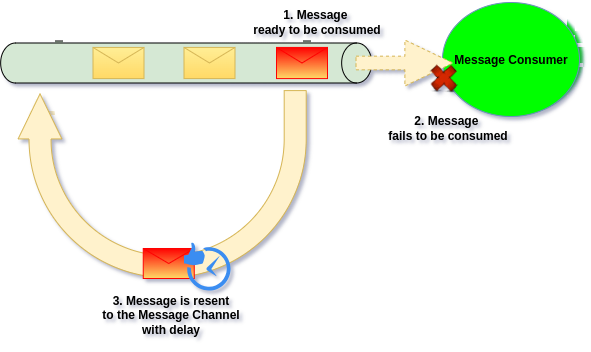
Use case
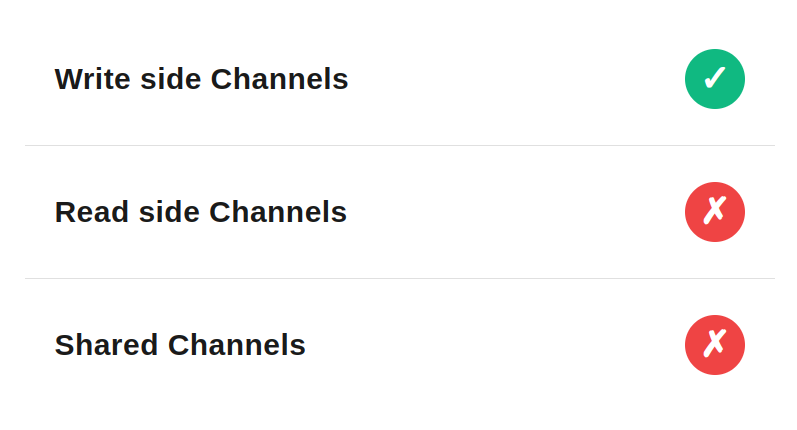
Sending Message back to the Channel, works well for “write” side logic, but not for “read” side logic and “shared channels”, as it duplicates the Message within the original Channel.
This solution is gold for “write side” action, as it solve most of transient errors without the need for manual intervention from Developers. For example if 3rd party went down for few minutes, if our retry strategy will define that message should be retried in 10 minutes, we will most likely recover the system automatically.
Real life implementation
Ecotone provides integration for resending Messages back to the channel with delay (if Message Broker supports that). We do it using ErrorChannel pointing to retry configuration.
/** RabbitMQ Consumer example */
#[ErrorChannel('delayedRetryChannel')] // define error channel
#[RabbitConsumer(
endpointId: 'transaction_handler',
queueName: 'transactions',
finalFailureStrategy: FinalFailureStrategy::RESEND
// Final failure strategy will be triggered in case sending to Error Channel fails
)]
public function processTransactionEvent(TransactionEvent $event): void
{
// Handle Transaction Event
}Then we define retry configuration, which will resend Message back to the original channel with delay:
#[ServiceContext]
public function errorConfiguration()
{
return ErrorHandlerConfiguration::create(
errorChannelName: "delayedRetryChannel",
delayedRetryTemplate: RetryTemplateBuilder::exponentialBackoff(
initialDelay: 100, // 100ms initial delay for testing
multiplier: 2 // Each retry is 2x longer (100ms, 200ms, 400ms...)
)->maxRetryAttempts(2), // Maximum 2 delayed retry attempts
);
}However in case of Message Channels that do not have ability to retry with delay like Kafka Streaming Channel, we need different way. For this we can combine custom database channel with retries.
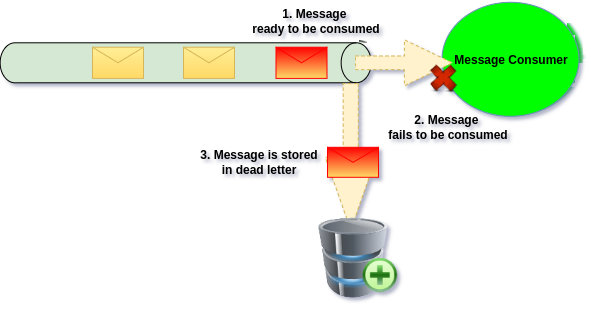
Dead Letter Strategy
When an unrecoverable failure occurs, retrying the message no longer adds value. At that point if Message can not be ignored, we should move the message to a some storage, which unblocks processing and prevents wasting resources on a message that cannot be handled successfully.
This storage which hold the Message for us for later review is called Dead Letter. Dead Letter can provide set of functionalities like retrying Message or deleting it.
Use case
This solution works nicely with “write” and “shared” channels. On failure we simply move the Message to Dead Letter and store it for later review. This however does not preserve processing order, therefore using it for “read side” channels won’t work well.
This is good approach when the original Channel is shared one, and we would like to move it to exclusive channel. This way the we will be able to use more failure recovery strategy patterns than we would be able to do on the first channel.
Real life implementation
In case of Ecotone Error Channel can actually act as our Dead Letter, we could implement our own Handler which will store the Message they way we want on failure.
However Ecotone with built-in Dead Letter in the database, that comes with operations like Message retrying and deleting. This works best with combing it with retries, to ensure few tries for automatic recover, and then in case of unrecoverable error pushing Message to dead letter:
#[ServiceContext]
public function errorConfiguration()
{
return ErrorHandlerConfiguration::createWithDeadLetterChannel(
errorChannelName: 'delayedRetryChannel',
delayedRetryTemplate: RetryTemplateBuilder::exponentialBackoff(1, 1)
->maxRetryAttempts(2)
deadLetterChannel: 'dbal_dead_letter' // push to predefined Ecotone Dead Letter
);
}Summary
The most important part of building asynchronous systems is matching your recovery approach to whether you’re building the write side (business actions that can’t stop) or read side (views that can be eventually consistent) of your system. Get this wrong, and you’ll either block critical business operations or corrupt your data views.
We’ve covered seven distinct failure recovery strategies — from simple Release and Ignore patterns to sophisticated approaches like Instant Retry, Delayed Resend, and Dead Letter handling. Each works brilliantly in specific scenarios but can be disastrous when misapplied. You can refer to this article article whenever needed, as it’s written in a way that you can simply jump to given given failure recovery strategy and then re-read it possible application.
For PHP based systems, Ecotone provides declarative, attribute-based integration with RabbitMQ and Kafka, handling all the complexity we discussed and more — automatic deduplication, transaction rollbacks, configurable retry strategies, and built-in dead letter management.
Join the Ecotone community on Discord to discuss message-driven architectures, get help with your integration challenges, and stay updated on new features: https://discord.gg/GwM2BSuXeg



